¡Hola! Mi nombre es Evgeniy Lyapustin, soy desarrollador senior en el equipo de visión por computadora. Junto con nuestros colegas de Yandex Research, hemos actualizado la red neuronal de difusión YandexART a la versión 1.3.
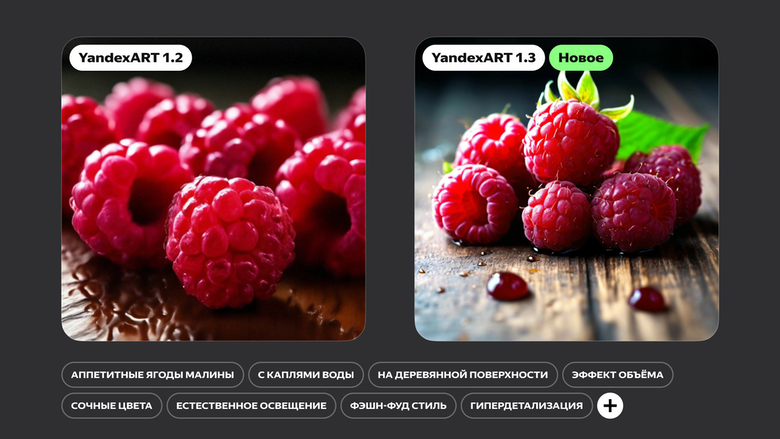
El principal cambio es que la red neuronal pasó a la tecnología de difusión latente. Además, el conjunto de datos en el que se entrenó el modelo se incrementó 2,5 veces. Gracias a esto, la nueva versión de YandexART comprende mejor las consultas de texto y crea imágenes aún más realistas.
YandexART 1.3 ya se utiliza en Masterpiece, cuyos usuarios ahora tienen la posibilidad de crear imágenes en diferentes formatos, como 16:9, 4:3 o 3:4. Posteriormente, la red neuronal actualizada comenzará a utilizarse en otros servicios de Yandex.
Con la difusión en cascada, la imagen mejora progresivamente al aumentar la resolución. La difusión latente funciona de manera diferente. Forma una representación latente intermedia de la imagen en forma de una descripción compacta que contiene información básica sobre la imagen en forma comprimida. Luego, la red neuronal expande el código en una imagen completa de alta resolución en un solo paso.
La tecnología de difusión latente consume menos recursos informáticos y permite crear gráficos más realistas. Lo hemos visto en la práctica. Entrenamos dos versiones del modelo en las condiciones más similares: cascada y latente. Y en cada etapa del entrenamiento, el latente ganó en mediciones de calidad y velocidad.
El conjunto de datos ha aumentado de 330 millones de pares de imagen y texto a más de 850 millones de pares. Para que el modelo comprenda mejor las solicitudes de los usuarios, se agregaron textos sintéticos al conjunto de datos en el que se entrenó: descripciones más detalladas de las imágenes generadas por la red neuronal. En la imagen de abajo puedes ver un ejemplo de texto sintético.
Además, para que YandexART tenga en cuenta más detalles del mensaje, el nuevo modelo utiliza no uno, sino dos codificadores de texto. El primero es nuestro codificador de la versión anterior 1.2, que fue entrenado para hacer coincidir pares de imagen y texto.
El segundo es nuevo para nosotros, basado en el código abierto umt5_xxl. A diferencia del primero, este codificador fue entrenado únicamente en textos. Dos codificadores diferentes dan al modelo señales de diferente naturaleza.
Según los resultados de las mediciones de SBS realizadas por los evaluadores de Yandex, la red neuronal YandexART 1.3 gana en el 57 por ciento de los casos en comparación con Midjourney V5.2 y en el 63 por ciento de los casos en comparación con la versión anterior de YandexART 1.2.
bbabo.Net